Running Large Language Models (LLMs) Locally
Large Language Models (LLMs) have revolutionized natural language processing by providing state-of-the-art performance in various tasks such as text generation, translation, summarization, and more. These models, like OpenAI's GPT, Google's BERT, Meta's LLaMA or Mixtral, are built on deep neural networks with billions of parameters, trained on vast amounts of data to understand and generate human-like text. Running LLMs locally allows developers to leverage their power without relying on cloud services, providing more control over data and reducing latency. It also gives you control over your network, especially if you want to fine-tune a model.
Parts of daily-digest.net are running on a local LLM. Instead of a big model like Mixtral, we have chosen OpenChat (https://github.com/openchatai/OpenChat ) which we have fine tuned to fit our needs.
Running LLMs Locally
Running LLMs on your local machine involves several steps, from choosing the right model to setting up the necessary software and hardware. Here’s a detailed guide to help you get started, focusing on Mixtral and using Olama as the easiest way to run LLMs locally. There are of course different ways to get your model to run locally, but Ollama is definitely the easiest one.
Tools and Frameworks
- Model Selection: Choose an appropriate LLM like Mixtral, or LLaMA (See https://ollama.com/library ). For this guide, we'll use Mixtral.
- Frameworks: Olama is a user-friendly tool designed to make running LLMs locally as simple as possible. It provides an easy setup and an openai compatible web API for interaction with the models.
Setting Up and Using Olama
Olama simplifies the process of running LLMs on your local machine. It allows you to pull and run various models with minimal configuration.
Steps to Install Olama on a Unix Machine
-
Install Olama:
curl -sSL https://ollama.com/install.sh | sh -
Initialize Olama and Pull Models: Olama supports pulling a wide range of pre-trained models, including Mixtral. https://ollama.com/library
ollama pull mixtral -
Run the Model: You can start the model server and interact with it via the provided web API.
ollama serve
Using Olama’s Web API
Olama provides a convenient web API to interact with the model. Here’s how you can use it:
-
Start Olama’s Web Server:
ollama serve -
Access the Web API: By default, the web server runs on
http://localhost:8000. You can send POST requests to this server to generate text. -
Example API Request:
curl -X POST "http://localhost:8000/generate" -H "Content-Type: application/json" -d '{"prompt": "Once upon a time", "max_length": 50}'
Benefits
- Data Privacy: Running models locally ensures that your data remains on your machine, providing better privacy.
- Reduced Latency: Local inference reduces the time taken to send requests to a server and wait for responses.
- Customization: Local deployment allows for easier customization and experimentation with models. that was one of the key reasons why we are using it
- Costs: Local deployment are often times cheaper, depending on the resources you're running it on
Pitfalls
- Resource Intensive: LLMs require significant computational resources, particularly for training.
- Hardware Requirements: High-end GPUs are often needed for efficient inference, and CPUs might be too slow.
- Maintenance: Local setups require regular maintenance and updates to the software and dependencies.
CPU Usage
Running LLMs on a CPU is possible but comes with significant drawbacks in terms of speed. CPUs are not optimized for the parallel processing required by deep learning models, leading to longer inference times. Most of the servers out there are not having a dedicated GPU, meaning CPU is all you have.
- Setup: Easier and more accessible for most users.
- Performance: Slow, especially for large models. Suitable for smaller models or less frequent tasks.
- Cost: Lower initial cost but higher time cost due to slow performance.
GPU Usage
GPUs are designed for parallel processing, making them ideal for running LLMs. They significantly speed up both training and inference.
- Setup: Requires a compatible GPU and proper drivers (e.g., CUDA for NVIDIA GPUs).
- Performance: Much faster than CPUs, capable of handling large models efficiently.
- Cost: Higher initial cost due to expensive hardware but lower time cost.
Speed Comparison: Mixtral on CPU vs. GPU
The graph below shows the inference time for a Mixtral model running on both CPU and GPU.
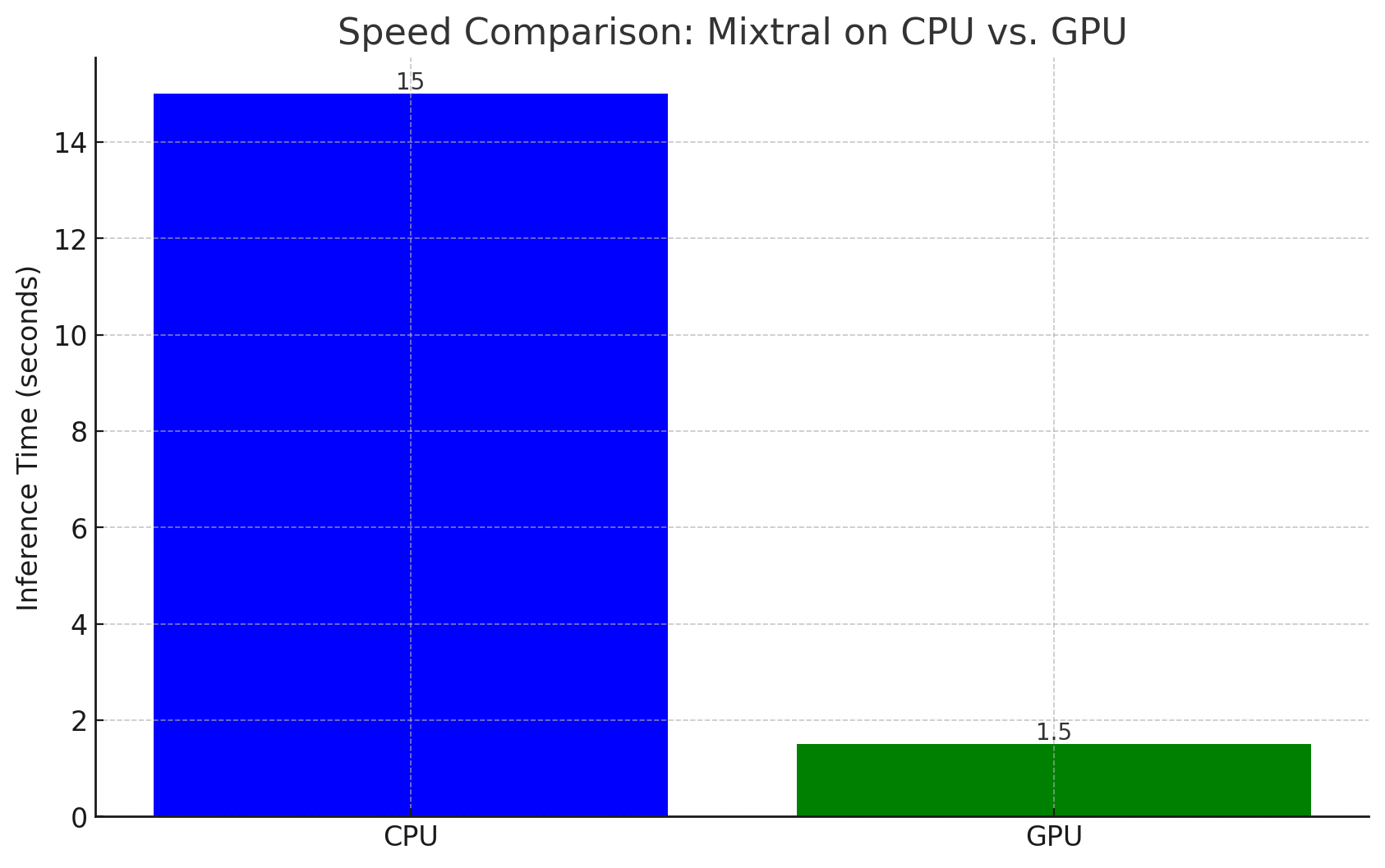
I ran the test on a Unix machine with 8 CPU cores and 32 gig of ram. Once with GPU mode disabled, once with GPU mode enabled. The difference is quite dramatic as expected.
From the graph, it is evident that GPUs can be up to 10-20 times faster than CPUs for LLM inference, depending on the model size and specific hardware.
What to Do If You Only Have a CPU
If you're limited to using a CPU, consider the following strategies:
- Model Optimization: Use techniques like model quantization and distillation to reduce the model size and improve inference speed.
- Batch Processing: Process multiple inputs simultaneously to make better use of the CPU's capabilities.
- Smaller Models: Opt for smaller models that require less computational power, like GPT-2 instead of GPT-3.
Conclusion
Running LLMs locally can provide significant benefits in terms of privacy, latency, and control. However, it requires careful consideration of the hardware and computational resources available. By using tools like Olama, you can simplify the setup and management of LLMs like Mixtral, making it easier to harness their power on your local machine, even with limited resources.
In one of our next blog posts, we will explain how to fine tune a specific model.